通过搭建mysql集群 来深入了解statefulset和其他Controller
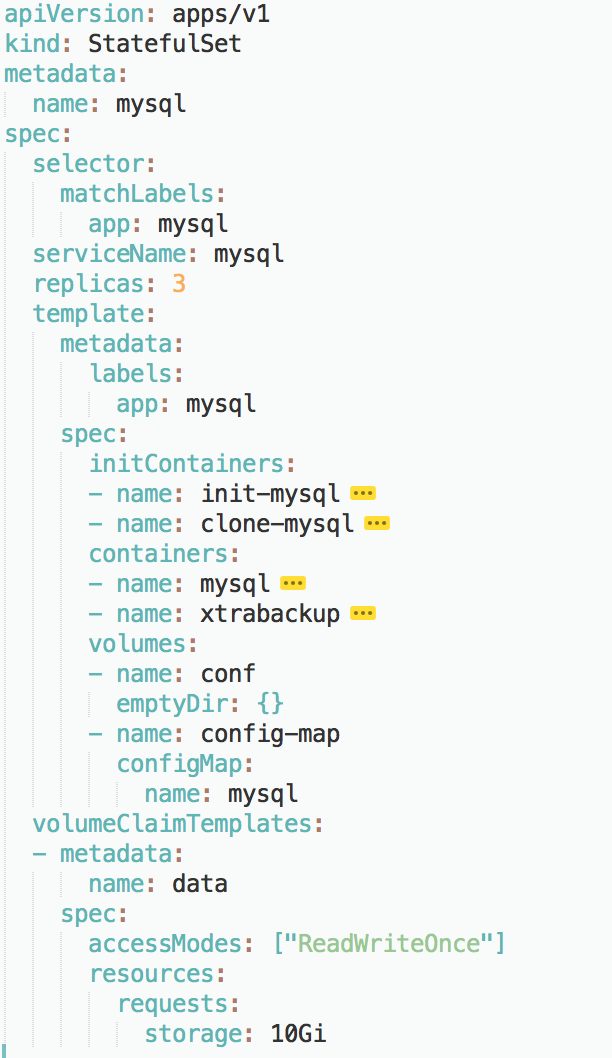
Statefulset最佳实践 <mysql集群> 需求 典型的主从模式 MySQL 集群
是一个“主从复制”(Maser-Slave Replication)的 MySQL 集群;
有 1 个主节点(Master);
有多个从节点(Slave);
从节点需要能水平扩展;
所有的写操作,只能在主节点上执行;读操作可以在所有节点上执行。
痛点
Master 节点和 Slave 节点需要有不同的配置文件(即:不同的 my.cnf);
Master 节点和 Slave 节点需要能够传输备份信息文件;
在 Slave 节点第一次启动之前,需要执行一些初始化 SQL 操作;
MySQL 本身同时拥有拓扑状态(主从节点的区别)和存储状态(MySQL 保存在本地的数据)
实践 1 ConfigMap
给主从节点分别准备两份不同的 MySQL 配置文件,然后根据 Pod 的序号(Index)挂载进去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: master.cnf: | # 主节点MySQL的配置文件 [mysqld] log-bin slave.cnf: | # 从节点MySQL的配置文件 [mysqld] super-read-only 定义了 master.cnf 和 slave.cnf 两个 MySQL 的配置文件。 master.cnf 开启了 log-bin,即:使用二进制日志文件的方式进行主从复制,这是一个标准的设置。 slave.cnf 的开启了 super-read-only,代表的是从节点会拒绝除了主节点的数据同步操作之外的所有写操作,即:它对用户是只读的。 ConfigMap 定义里的 data 部分,是 Key-Value 格式的。比如,master.cnf 就是这份配置数据的 Key,而“|”后面的内容,就是这份配置数据的 Value。这份数据将来挂载进 Master 节点对应的 Pod 后,就会在 Volume 目录里生成一个叫作 master.cnf 的文件。
2 Service
创建两个 Service 来供 StatefulSet 以及用户使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 apiVersion: v1 kind: Service metadata: name: mysql labels: app: mysql spec: ports: - name: mysql port: 3306 clusterIP: None selector: app: mysql --- apiVersion: v1 kind: Service metadata: name: mysql-read labels: app: mysql spec: ports: - name: mysql port: 3306 selector: app: mysql 这两个 Service 都代理了所有携带 app=mysql 标签的 Pod,也就是所有的 MySQL Pod。 端口映射都是用 Service 的 3306 端口对应 Pod 的 3306 端口。不同的是,第一个名叫“mysql”的 Service 是一个 Headless Service(即:clusterIP= None)。 所以它的作用,是通过为 Pod 分配 DNS 记录来固定它的拓扑状态,比如“mysql-0.mysql”和“mysql-1.mysql”这样的 DNS 名字。 其中,编号为 0 的节点就是我们的主节点。而第二个名叫“mysql-read”的 Service,则是一个常规的 Service。并且我们规定,所有用户的读请求,都必须访问第二个 Service 被自动分配的 DNS 记录,即:“mysql-read”(当然,也可以访问这个 Service 的 VIP)。 这样,读请求就可以被转发到任意一个 MySQL 的主节点或者从节点上。备注:Kubernetes 中的所有 Service、Pod 对象,都会被自动分配同名的 DNS 记录。 而所有用户的写请求,则必须直接以 DNS 记录的方式访问到 MySQL 的主节点,也就是:“mysql-0.mysql“这条 DNS 记录。
3 字段设计
selector : 这个 StatefulSet 要管理的 Pod 必须携带 app=mysql 标签;它声明要使用的 Headless Service 的名字是:mysql。
replicas :3 ,表示它定义的 MySQL 集群有三个节点:一个 Master 节点,两个 Slave 节点。
PVC :
resources.requests.strorage 指定了存储的大小为 10 GiB;
ReadWriteOnce 指定了该存储的属性为可读写,并且一个 PV 只允许挂载在一个宿主机上。将来,这个 PV 对应的的 Volume 就会充当 MySQL Pod 的存储数据目录。
4 sidecar 在 Slave 节点的 MySQL 容器第一次启动之前,执行初始化 SQL。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 ... # template.spec.containers - name: xtrabackup image: gcr.io/google-samples/xtrabackup:1.0 ports: - name: xtrabackup containerPort: 3307 command: - bash - "-c" - | set -ex cd /var/lib/mysql # 从备份信息文件里读取MASTER_LOG_FILEM和MASTER_LOG_POS这两个字段的值,用来拼装集群初始化SQL if [[ -f xtrabackup_slave_info ]]; then # 如果xtrabackup_slave_info文件存在,说明这个备份数据来自于另一个Slave节点。这种情况下,XtraBackup工具在备份的时候,就已经在这个文件里自动生成了"CHANGE MASTER TO" SQL语句。所以,我们只需要把这个文件重命名为change_master_to.sql.in,后面直接使用即可 mv xtrabackup_slave_info change_master_to.sql.in # 所以,也就用不着xtrabackup_binlog_info了 rm -f xtrabackup_binlog_info elif [[ -f xtrabackup_binlog_info ]]; then # 如果只存在xtrabackup_binlog_inf文件,那说明备份来自于Master节点,我们就需要解析这个备份信息文件,读取所需的两个字段的值 [[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1 rm xtrabackup_binlog_info # 把两个字段的值拼装成SQL,写入change_master_to.sql.in文件 echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\ MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in fi # 如果change_master_to.sql.in,就意味着需要做集群初始化工作 if [[ -f change_master_to.sql.in ]]; then # 但一定要先等MySQL容器启动之后才能进行下一步连接MySQL的操作 echo "Waiting for mysqld to be ready (accepting connections)" until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done echo "Initializing replication from clone position" # 将文件change_master_to.sql.in改个名字,防止这个Container重启的时候,因为又找到了change_master_to.sql.in,从而重复执行一遍这个初始化流程 mv change_master_to.sql.in change_master_to.sql.orig # 使用change_master_to.sql.orig的内容,也是就是前面拼装的SQL,组成一个完整的初始化和启动Slave的SQL语句 mysql -h 127.0.0.1 <<EOF $(<change_master_to.sql.orig), MASTER_HOST='mysql-0.mysql', MASTER_USER='root', MASTER_PASSWORD='', MASTER_CONNECT_RETRY=10; START SLAVE; EOF fi # 使用ncat监听3307端口。它的作用是,在收到传输请求的时候,直接执行"xtrabackup --backup"命令,备份MySQL的数据并发送给请求者 exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \ "xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root" volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d
xtrabackup 的 sidecar 容器的启动命令里,其实实现了两部分工作。
如果有,则说明这个目录下的备份数据是由一个 Slave 节点生成的。这种情况下,XtraBackup 工具在备份的时候,就已经在这个文件里自动生成了”CHANGE MASTER TO” SQL 语句。所以,我们只需要把这个文件重命名为 change_master_to.sql.in,后面直接使用即可。
如果没有 xtrabackup_slave_info 文件、但是存在 xtrabackup_binlog_info 文件,那就说明备份数据来自于 Master 节点。这种情况下,sidecar 容器就需要解析这个备份信息文件,读取 MASTER_LOG_FILE 和 MASTER_LOG_POS 这两个字段的值,用它们拼装出初始化 SQL 语句,然后把这句 SQL 写入到 change_master_to.sql.in 文件中。
接下来,sidecar 容器就可以执行初始化了。从上面的叙述中可以看到,只要这个 change_master_to.sql.in 文件存在,那就说明接下来需要进行集群初始化操作。所以,这时候,sidecar 容器只需要读取并执行 change_master_to.sql.in 里面的“CHANGE MASTER TO”指令,再执行一句 START SLAVE 命令,一个 Slave 节点就被成功启动了。
5 mysql pod 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ... # template.spec containers: - name: mysql image: mysql:5.7 env: - name: MYSQL_ALLOW_EMPTY_PASSWORD value: "1" ports: - name: mysql containerPort: 3306 volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 500m memory: 1Gi livenessProbe: exec: command: ["mysqladmin", "ping"] initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 readinessProbe: exec: # 通过TCP连接的方式进行健康检查 command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"] initialDelaySeconds: 5 periodSeconds: 2 timeoutSeconds: 1
数据目录是 /var/lib/mysql
配置文件目录是 /etc/mysql/conf.d
如果 MySQL 容器是 Slave 节点的话,它的数据目录里的数据,就来自于 InitContainer 从其他节点里拷贝而来的备份.
它的配置文件目录 /etc/mysql/conf.d 里的内容,则来自于 ConfigMap 对应的 Volume.
而它的初始化工作,则是由同一个 Pod 里的 sidecar 容器完成的.
livenessProbe,通过 mysqladmin ping 命令来检查它是否健康.
readinessProbe,通过查询 SQL(select 1)来检查 MySQL 服务是否可用。
6 创建PV
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ kubectl create -f rook-storage.yaml $ cat rook-storage.yaml apiVersion: ceph.rook.io/v1beta1 kind: Pool metadata: name: replicapool namespace: rook-ceph spec: replicated: size: 3 --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: rook-ceph-block provisioner: ceph.rook.io/block parameters: pool: replicapool clusterNamespace: rook-ceph
StorageClass :自动地为集群里存在的每一个 PVC,调用存储插件(Rook)创建对应的 PV,从而省去了我们手动创建 PV 的机械劳动。
在使用 Rook 的情况下,mysql-statefulset.yaml 里的 volumeClaimTemplates 字段需要加上声明 storageClassName=rook-ceph-block,才能使用到这个 Rook 提供的持久化存储。
1 2 3 4 5 6 7 $ kubectl create -f mysql-statefulset.yaml $ kubectl get pod -l app=mysql NAME READY STATUS RESTARTS AGE mysql-0 2/2 Running 0 2m mysql-1 2/2 Running 0 1m mysql-2 2/2 Running 0 1m
总结
StatefulSet 其实是一种特殊的 Deployment,只不过这个“Deployment”的每个 Pod 实例的名字里,都携带了一个唯一并且固定的编号。这个编号的顺序,固定了 Pod 的拓扑关系;这个编号对应的 DNS 记录,固定了 Pod 的访问方式;这个编号对应的 PV,绑定了 Pod 与持久化存储的关系。
sidecar的意义:容器是单进程 一个容器里显然没办法管理两个常驻进程 所以sidecar是常驻进程,要监听3370端口 数据复制操作要用sidecar容器来处理,而不用mysql主容器来一并解决。
kubernetes最小的管理单位是pod的概念,把思维从容器这层抽出来。然后也更清楚的理解了statefulset实现有状态,就是把特定的状态配置绑定在某个对象名称上面,然后通过control loop不断的维护这个对象的特性,只要这写特定对象和它们各自绑定的状态配置不变就实现了有状态的应用部署和维护。
文章是一个statefulset分饰两个角色。个人感觉master和slave做成两个statefulset就easy很多。
再次证实我的名言 “你所谓的‘本质’是由你认知的高度决定的”。当我学到operator的时候再回过头看这个就太zz了。。。